A Tour Of The Loom

The main goal of this project is to achieve high throughput with lightweight concurrency with minimal effort in writing code.
Why Virtual Thread? virtual thread requires cheap resources compared to traditional Platform Thread which is the wrapper of OS thread. Besides virtual thread is a simple implementation of JDK threads, that are not OS threads.
The application that contains the executor Thread Poll can be replaced with an executor that creates a new virtual Thread for each task. We can achieve this support with a minor change, that is the beauty of the new threading model.
Unlike a Platform thread, blocking a virtual thread is cheap, Platform thread is a wrapper of an OS thread that has some limitations like OS can only allow a limited number of thread creations.
How does traditional Thread Pool work? Let’s examine Platform thread behavior with newFixedThreadPool Executor. Suppose thread pool size is one. Two runnable tasks are submitted to the thread pool, the first task will execute first, and once execution is over 2nd task will be started processing. The major limitation is we cannot be able to execute or schedule both tasks at a time.
How does Virtual Thread Works? Suppose we have declared newVirtualThreadPerTaskExecutor Executors that accept a task and span a new virtual thread. For instance, we have submitted two tasks, both tasks will be scheduled by virtual thread schedulers if 2nd task response is prepared first then the result will be returned asynchronously.
Let’s discuss a real scenario: Service to Service communication. The main goal of the HTTP server is to serve responses corresponding to requests, most of the time they have to perform I/O bound operations like reading data from a network or even from its own file system. Definitely, I/O bound operation is costly, additionally, synchronous operation is not suitable in such a scenario as the CPU has to be idle while performing i/o operation. asynchronous programming can solve this problem. Currently, we can get support from Project Reactor or Akkha. Though that rich library has multiple use cases, today I will examine how virtual thread can solve the traditional thread pool problem.
The idea is quite simple, I write two services the first service will call the second service(service to service communication), and when the response gets from the second service first service will prepare the final response.
The implementation of service one has two versions. The first version examines the traditional fixed thread pool executor service. version two migrates with virtual thread poll. I will try to compare both versions’ performance. V1
import java.net.Socket;
import java.time.LocalDateTime;
import java.util.concurrent.Callable;
import java.util.concurrent.Executors;
import java.util.logging.Logger;
public class TomCatApp {
private static final Logger LOGGER = Logger.getLogger(TomCatApp.class.getName());
public static void main(String[] args) {
AcceptRequest acceptRequest = new AcceptRequest(Config.getInstance().getPort());
//acceptRequestThread
Thread t = new Thread(acceptRequest);
t.setName("Old school App");
t.start();
int requestProcessor = Config.getInstance().getRequestProcessor();
ProcessRequest processRequest = new ProcessRequest();
try (var executor = Executors.newFixedThreadPool(1)) {
LOGGER.info("request processor is ready to process requests");
while (true) {
try {
Socket socket = LoomCatApp.SOCKET_QUEUE.take();
LOGGER.info("new request" + LocalDateTime.now());
Runnable runnable = () -> processRequest.startProcessing(socket);
executor.submit(runnable);
} catch (InterruptedException e) {
LOGGER.info(e.getLocalizedMessage());
e.printStackTrace();
}
}
}
}
}
this application accepts requests from the browser or postman client. submit a runnable task to the thread pool. as the thread pool size is one so that one request can be served at a time. this service one call service two. service two will return a response per request after 50 milliseconds of delay. The task submitted to the first services thread pool must have to wait until getting a response from service two. that is why the waiting time period is a minimum of 50 milliseconds. If 100 milliseconds is required to serve 2 requests then the maximum throughput can be generated as 20. The load tests result are given below.
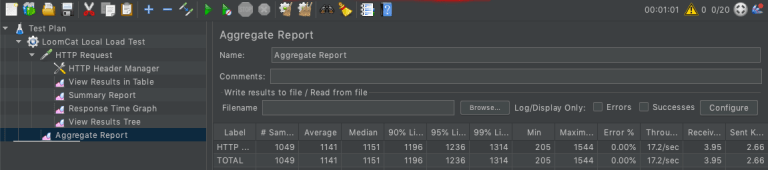
Single user concurrently requesting the service for 60 seconds, actual generated throughput is 17.2 which is closer to 20. If we increase the number of user throughput cannot be increased. If we increase pool size like 4, the generated query per second will be actual * 4.
Throughput (Query per second) -> 17.2
Average 1141 ms
Total request 1049
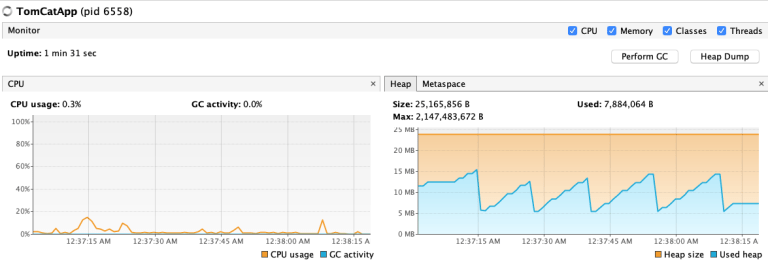
The figure illustrates that the CPU spent almost idle time. The main cause is to wait 50 seconds to get a response from service two.
V2 with virtual thread pool
import java.net.Socket;
import java.time.LocalDateTime;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.logging.Logger;
public class LoomCatApp {
public static LinkedBlockingQueue<Socket> SOCKET_QUEUE = new LinkedBlockingQueue<>();
private static Logger LOGGER = Logger.getLogger(LoomCatApp.class.getName());
public static void main(String[] args) {
AcceptRequest acceptRequest = new AcceptRequest(Config.getInstance().getPort());
//acceptRequestThread
Thread t = new Thread(acceptRequest);
t.setName("Loom App");
t.start();
ProcessRequest processRequest = new ProcessRequest();
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
LOGGER.info("request processor is ready to process requests");
while (true) {
try {
Socket socket = SOCKET_QUEUE.take();
LOGGER.info("new request" + LocalDateTime.now());
executor.submit(() -> processRequest.startProcessing(socket));
} catch (InterruptedException e) {
LOGGER.info(e.getLocalizedMessage());
e.printStackTrace();
}
}
}
}
}
this application accepts requests from the browser or postman client. this time we create newVirtualThreadPerTaskExecutor. this way we do not need to add this to the pool. as a result per task span a new virtual thread. this way we do not need to add this to the pool. so that multiple requests can be served at a time. this service one call service two. service two will return a response per request after 50 milliseconds of delay. that is why the waiting time period is a minimum of 50 milliseconds per request. The first services task submitted to the executor must have to wait until getting a response from service two. When the task is submitted to the scheduler, it will mount its platform thread, which works as a virtual thread carrier, but this time after calling service two this virtual thread will be unmounted from the platform thread. once the response return from service two, again virtual thread will be mounted with the platform thread and render the final response from service one. Not a single task will depend on each other. The tasks will independently be executed. as a result, the performance has dramatic rise. with this model, we can generate a significant amount of throughput.
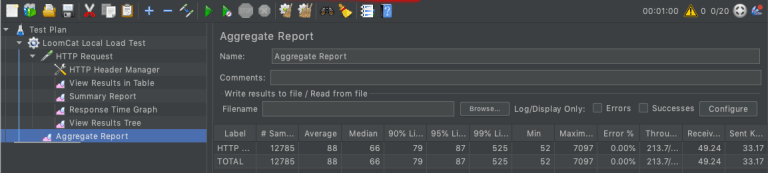
20 users concurrently requesting the service for 60 seconds, the actual generated throughput is 213. If we increase the number of user throughput also be increased.
Throughput (Query per second) -> 213
Average 88 ms
Total request 12785
CPU consumption rate
CPU is not idle in this case. The main cause is he has to do something during this execution time.

আল্লাহ হাফেজ